| �@ | �@ | �@ | |
|
|
�ï��¤� Enzyme Analysis 8 �J�ս��� Protein Technology |
�� ���G��Ǭ�s - �ï������ - �� �� |
�`�ؿ� �� �W�Һ� �� �U���� �� |
| �@ | �@ | �@ |
�ѦҸ귽 |
|
�� �� |
8.1 ���l�q���w 8.2 �J�ս�c�y�P�զ� N-�ݩ� C-�� �i��IJզ� �i��ĩw�� �`肽���� ��L��k 8.3 �K�̾Ǥu�� �ܭ�s�� �K�̬y�{ ���^�s�� ���^���� 8.4 �J�ս�s��� |
�G�����q�a���O�J�ս��ު����n�u�� |
�U�� [���� pdf] [Protein] {BCbasic} �s���ͪ��ƾǰ�¦ �@ |
| �@ | �@ | �@ | |


|
8 �J�ս��� |
�ѦҸ귽 |
|
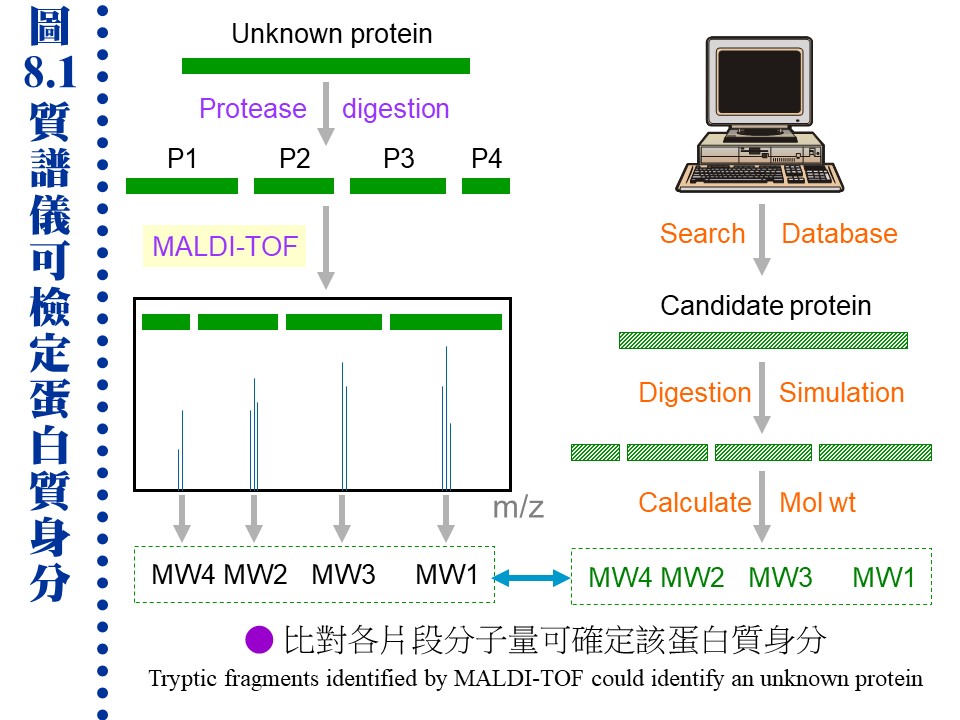
�J�ս�O�ӭM���̭��n���\��ʥ����l�A�h�~�ӹ�J�ս�o�i�X�\�h��s��ޡA�ר�O���w�J�ս���l�q�B���l�c�y�P�զ��B�L�q�¤ƻP�˩w���A��i���ͱM�@�ʧ��^�@�����w�A�o�i�L�y�^���x���ֳt�z�ˤu��A�ϱo�s���J�ս����ޫD�`�h�ˤƥB��j�j�¤O�C�����i���O��X�e���U��¦�ާ@���`���P���ΡA�]�i�@�B��J���Q�`�^�J�ս誺�����C 8.1 ���l�q���w�G���l�q�O�J�ս�̰ʽ褧�@�A���\�h�ش��w�k�A�̦n�ĥμƭӤ�k�ۤ����ҡC a. ���l�c�Ϊ��v�T�G ���^�L�o�O�� ���l�^�n ���j�p�Ӷi������A�]���Y��سJ�ս誺���l�q�����ۦP�A���c�θ����P���̱N���������X�ӡA�|���{�X����������l�q�C b. �зdzJ�ս� (molecular weight marker)�G ���^�L�o�k�ݥ��Τw�����l�q���зdzJ�ս�A�D�X�зǮե��u�A�A�H�����k�D�o�˥������l�q�C�ӫ~�����зǤ��l�q���J�ս�V�X�G�A�ϥΤW����K�C�зdzJ�ս誺�ϥΰѦ� (kD)�G Thyroglobulin (669, 330), ferritin (440), catalase (232), immunoglobulin G (160), lactate dehydrogenase (140), serum albumin (67), ovalbumin (43), lactalbumin (14.4) c. Blue Dextran 2000�G �O�@���ŦⰪ���l�E�� (���l�q�� 2,000 kD)�A�L�k�i�J���y�դ��A�|�b void volume (Vo) �����X�ӡA���Ŧ��a�]�i�Ψ��ˬd�ެW���˶�O�_�����CBlue Dextran ��J�ս観�۷��j���l���ʡA���n�P�˥��V�X�b�@�_�i�潦�^�L�o�C�����w�IJG�����l�@�צܤ֭n�b 0.1~0.2 M �H�W (�K�[ NaCl)�A�H�J�A���^�����J�ս誺�l���O�C d. �ެW����n�O���کw�G (1) �H���^�L�o�k���w�J�ս誺���l�q�ɡA�s�P�зǫ~�μ˥��J�ս�A�e��n���Ʀ��ެW�ާ@�A�b�o�����ެW���ާ@����n�O�����w�A���y���~���s�˶�A�]���^�� Vo ������i��|���ܡC (2) �H HPLC �� FPLC �������^�L�o�k�i����l�q���w�A�i�٥h�ܦh�ɶ��ӥB�ǽT�A�O�̨Ϊ���ܡC ��������q�a�O�⽦�^�����ѤW��U�@���W����סA�佦�^�ծ|�V�ӶV�p�A�J�ս���l�q�V�p�]�o�V���A�]�����l�q�j�p�N�����a�ʲv���M�w�]���C��q�a�]�P���^�L�o�@�ˡA�n���зǤ��l�q���J�ս谵����A�~��w�X�˥������l�q�C a. ��A���ܩʡG ��q�a�i�� disc-PAGE �� SDS-PAGE ��ؤ覡�A������M�i���w�ܩʳJ�ս誺���^���l�q�A���Y�w�M�˥��B�z�ɪ��ܩʱ���A�h���ɥi��ݨ�h���^���l�C b. �J�ս赥�q�I���v�T�G ��A����� disc-PAGE ���M�O�̷Ӽ˥����l�q�j�p�i������A���Y�J�ս���l���a�b�q���A�ƩΦ] pI �Ӱ��ӱa�ۤϹq���A�h�o�ر�q�a�N���A�ΡC��� SDS-PAGE �h�L�q�������D�A���G�Ƭ��i�a�C c. ���G�P�w�G �H��� disc-PAGE �w��A���l�q�A�� pI ���C���J�ս� (4~6 ����)�A�T�꦳�۷������ǽT�סA���٭n�ν��^�L�o�k�T�{�C�i���q�a�ɡA�i��@��q�a�h�]�@�Ǯɶ��A�V�ƶ]�X���^�]�L���A�]���J�ս�|�d�b���K�����^���A�H�W�[�ѪR�O�C�b�����פ夤�A���n�H��A���^�q�a�����˩w���l�q���ߤ@�̾ڡC 8.1.3��L���l�q���w��k�G 8.1.3.1 �W���t���ߪk�G(�Ѧ� 3.2) a. �I���Y���G�J�ս�b�K�ױ�ת����褤�i��W���t���߮ɡA��I���t�v (S) �P ���l�q�B���l�K�� �P ���l�Ϊ� �����A�]���i�ΨӴ��w���l�q�C b. �W���t���ߪk�]�i�����@�ػï��s�Ƥ�k�A�b�ï��¤Ƥ�k�����Բӻ����C 8.1.3.2 ���i��ħǦC�p����l�q�G a. �\�h�J�ս�w����ֻ� (cDNA) �ǦC�A�Ѧ��i���o���i��ħǦC�A�H�q���p��o���i��ħǦC�����l�q�A�Y���ӳJ�ս誺���l�q�C�����`�N�ܦh�ï��O�H�h���^���A�s�b�A���A���l�q�N�|�j�ܦh�A�n�H��L��k���ҡC b. �`�N�j�����J�ս賣�� ��Ķ��� (post-translational modification)�A�Ҧp�J�թΦ��䥦����� (��酶)�A�h��ڤ��l�q���ӷ|�j�@�ǡC�Ϥ��A�Y����Ķ�᪺�J�ս���ѡA�h���l�q�S�|�ܤp�@�I�C 8.1.3.3 ���л����R�G a. ���л��i��T���w�U�ؤ��l����q�A�̪�]�Q�ΨӴ��w�J�ս誺���l�q�A�Ʀܥi�M�w���i��ħǦC�A�o�اN�w�ͦ����A�i�w�X 30 �ӥH�W���i��ħǦC�A�b�J�ս��^�Ǫ����ΡA�良���J�ս誺����Ų�w�O�����n�u��C b. MALDI-TOF (matrix-assisted laser desorption/ionization time-of-flight) �O���Ф��R���@�ر`�Τ覡�A���⥼���J�ս�H�J��酶���Ѧ��p���q�`肽�A�o�Ǥ��q�i�H�b MALDI-TOF ���л������O�w�X����l�q�A�A�P�w����Ʈw����A�N�i�H���������J�ս誺���� (�� 8.1)�C
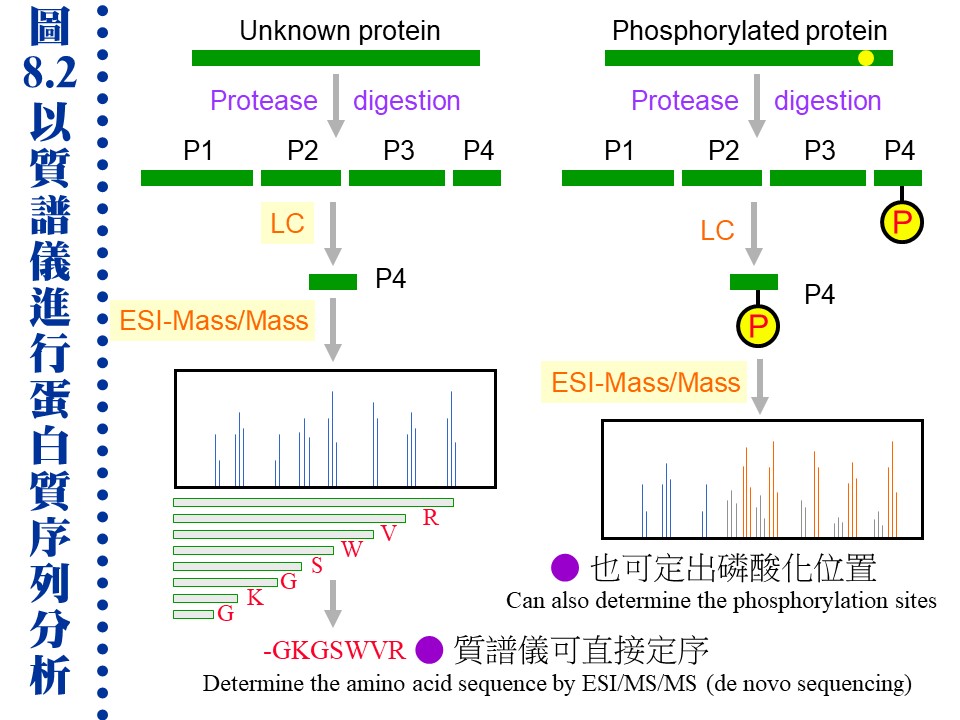
(�C�i�ϧ��s���� 960 x 720 �M������) c. �J�ս褴�M���γJ��酶���Ѧ��`肽�A�����X�C�q�`肽��A�A�H�t�@�� EI (electron ionization) ���л��i�@�B�����`肽�ᰩ����p�H���A���R�U�H������q�i���o�o�@�q�`肽���i��ħǦC�A�A��C�q�`肽���i��ħǦC��s�_�ӡA�N�i�H�o���ӳJ�ս誺�ǦC�P���l�q (�� 8.2 �� de novo sequencing)�C�Y�J�ս�W�����C�ĤƵ����A�]�i�H���o���l�q���W�[�A�]�ӱ��o�C�Ĥƪ���m (�� 8.2 �k)�C
|
�@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ |
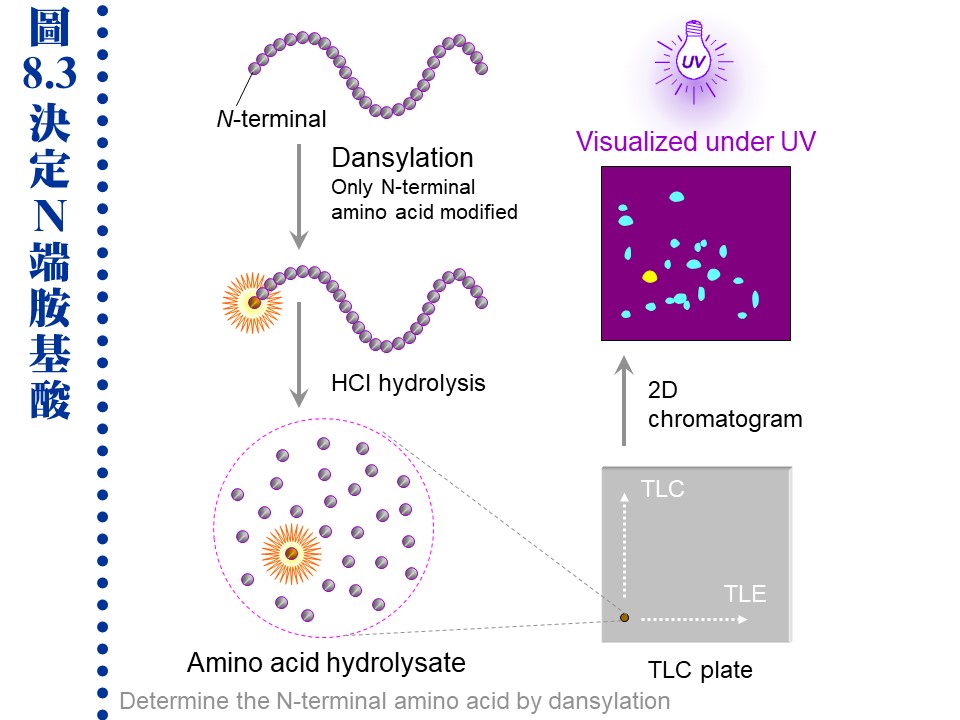
8.2 �J�ս�c�y�P�զ��G�H�U�U���˩w��k�A�ݭn�«������J�ս�A�̦n���H�@�몺�h�R�k�¤ƫ�A�A�λs�Ʀ��q�a�o�짡��J�ս�C�䤤�ܦh�����|�P�i������A�]���˥�������i���� (�p Tris �Υ����i���)�A�H�K�z�Z�����C 8.2.1 N-�ݩ� C-���i��ġG �{�b�w�g�ܤֳ�W���w N-�ݡA�q�`�������h�w�ǡC a. �@��J�ս賣���T�w�� N-�ݤ� C-�ݡAN-���i��ĥi�ϥ� dansylation �ХH dansyl ��ΡA�A�H HCl ���ѳJ�ս�C���F dansylation �~�A�|���\�h�����������i�Ψ��˩w N-���i��� (�� 8.3)�C
b. ���ѩұo�������i��ĥH polyamide (TLC plate) �i�� ���V���h�h�R �����A�Ц� dansyl ���i��Ħb UV ���U�|�o�X�å��A�P�w���� 20 �� dansyl �i��Ĥ���A�Y�i�P�w�i��ĺ����A��i�� HPLC �T�w�i��ġC c. ���dzJ�ս誺 N-���i��i��g�A�Q�ƭ��Ӫ�ê (blocked)�A�L�k�i������A�ץH�Ӫ��ӷ����J�ս�S�O�`���C�J�����ΡA�i��n���X�`肽���q�өw�� (�} N-��)�A�Ϊ̥H�ƾǤ����h�����@���C d. ���dzJ�ս�t���Ʊ��`肽��A��������s���_�� (�p chymotrypsin)�A�]���|���ƭ� N-���i��ġC�h�n�����_������A��������U�q�`肽���}��A�A���O�w�ǡC e. C-�ݥi�Υ~��酶 carboxylpeptidase �@�Ӥ@�Ӥ��U�ӡA�A�i���i��Ĵ��w�A���i��ĥX�{���h�趶�ǡA�Y�i�o�� C-�ݧǦC�C���]�o�ؤ��Ѥ������n����A�����`�ΡC 8.2.2 �i��IJզ��G a. �J�ս�H 6 N HCl �� 4 N methanesulfonic acid �b�u�� 110�J �U���� 24 h�A���ѲG�H���l�洫 HPLC ���}�U���i��ġA�ä��O���w��t�q�A�i�o���U�i��Ī��ʤ��զ��C b. ���i��Ħʤ��զ������P�A�Y�i�����سJ�ս誺�ۦ��ʡA�ño���J�ս�c�y���ʽ�P�S�x�C�Ҧp���@���X�J�� metallothionein �t���ܰ��q�� Cys�A�K�O�H Cys �P�X�C c. �ϥ� HCl ���ѳJ�ս�|�}�a tryptophan�A�åB�� glutamine �� asparagine ���h�i��A���� glutamic acid (�X�� Glx) �� aspartic acid (�X�� Asx)�A���R�ɭn�`�N�o�Ǩƹ�C�P�ɡA�˥��νw�IJG���n�קK�Ӧh�i���� (�p Tris)�A�H�K�z�Z HPLC ���R�C 8.2.3 �i��ĩw�Ǫk�G �i��ħǦC�O�@�ӳJ�ս�̭��n�B����T�A���F�W�z���л��w�� (8.1.3.3) ���~�A�٦���ؤ�k�i�D�o�i��ħǦC�C 8.2.3.1 cDNA �����k�G �ѳJ�ս��]����苷�ħǦC�A�i���o���i��ħǦC�A�O�ثe�̱`�Ϊ��w�Ǥ�k (reverse biochemistry)�C����]�@���ަ� cDNA �w�A�b�g�L�s�ޡB�w�ǵ��u�@�A��Ķ���J�ս誺�i��ħǦC��A�N�i�i��t�Ωʪ����R�u�@�F�q�`�H�q���{���j�M���A�Ҧp GCG (Genetics Computer Group �u�@��)�C ������n�α`�������R���ئp�U�G a. �ǦCŲ�w�G �Y�������J�ս�A�h�i�J�J�ս��Ʈw (Protein Data Bank, PDB) �j�M�A�P�w�����ǦC���A�i�o���A���J�ս�O�w�g�Q�o�{���A�άO�@�ӷs���J�ս�C�q�`���i���o�������J�ս�ǦC�A�M������������J�ս誺�i��\��C b. �G�źc�y���R�G �Ѥ@���i��ħǦC�A�i�w���J�ս誺�G�źc�y�A���o�Ͳz�\��W�����Y�C�q�`�T�ť��^�c�y�L�k��T�w���A���D���@�Ӥw���c�y�������J�ս�i�ѰѦҡC c. �\��ǦC���R�G �\�h�S�w���i��Ĥ��q�A���S�w���Ͳz�\��A�٬� signature�C�Y����Y�ǥ\��ǦC�A�h�i�������J�ս誺�i��Ͳz����C���| signature �p�G�U�ضi�J�M�����ǦC�BPEST ���ѧǦC�B������^���ǦC (KDEL) ���C d. �@��ʽ���R�G ���i��ħǦC�i���X���J�ս誺���q�I�B���l�q�B�ܭ�M�w����q�B�U�سJ��酶�������I�����θ�ơA�ثe�����q���M�˳n�^�i��T�w���C 8.2.3.2 Edman �����w�ǡG �@�Ӥ@�ӧ��i��ıq N-�ݤ��U�ӡA�M�᪽���w�X������C a. Edman �����G ���� dansylation �� N-�ݼХܤ����A���O�ϥ� PITC (phenylisothiocyanate) �b�J�ս誺 N-�ݶi��������A�ͦ� PTH �l�ͪ��AEdman �����᪺ N-���i��ĥi�H�Q���U�ӡA�A�H HPLC �˩w������i��ġC�Ѿl���J�ս賡���i�H�~��ĤG�� Edman �����A�q�`��ʥi�i�� 10-30 �Ӵ`�� (�� 8.4)�A�w�X���i��ħǦC�C
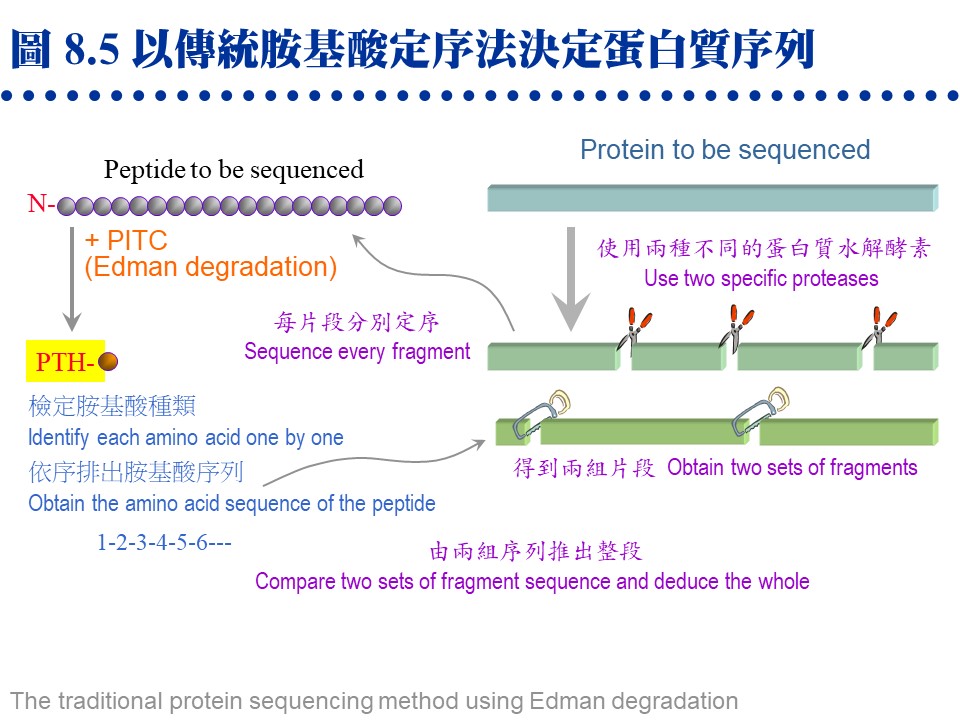
b. �۰ʩw�ǡG �ثe���H�۰ʩw�ǻ��i��A�åB��˥��J�ս�T�w�b�����W�A��K�F�ӡC�i�b�q�a����L���ֺ��ȤW�A���X�ҭn����a�A�����W���w�ǡC c. �w�Ǥ��e����ơG (1) �ˬd�J�ս誺���l�q�Υ|�źc�y�A�Y������h���^�A�n�����X����椸�^�C (2) �Y�����l���Τ��l�� ������ �s���A�����٭줧�A�H�Ѷ}�T�źc�y�C (3) ���L�Ҥ��ƦX���B�赥������A�Ψ㦳 prosthetic group�C (4) ���l�q�Ӥj���J�ս����������p���q�A�ä����o�U�`肽���q�A���O�w�ǡC d. �����w�Ǫ����D�G (1) �J�ս�n�������`肽�G �ѩ�w�dz̦h�u��i�� 50 �Ӵ`���A�ӳJ�ս�q�`���Ʀʭ��i��Ĥ��h�A�]�������J�ս�n�������\�h�p���q�A�����X�U�Ӥp���q��A�i��w�ǡC (2) �n�Ψ�M���P���`肽���G ���w�X�U�W�ߤ��q���ǦC��A�L�k�o���U���q�����ᦸ�����Y�C�]���n�H��ؤ��P�M�@�ʪ��J��酶�A�s�@��դ��P���p���q�A��ժ����I���P�A�H�K�b���O�w�ǫ�ۤ�ﭫ�|�����A��X����q���s���I (���U�`)�C 8.2.4 �`肽���СG a. �M�@�ʳJ��酶�G �i��J�ս誺�S�w�i��Ķi����ѡA�o��@�s���P���u���`肽���q�C��Ӥ��P�J�ս�g�P�@�سJ��酶���ѡA�ұo�����`肽�s�A��肽��ƥءB�U�q�`肽���i��IJզ��P���u�����ۦP�A�iŲ�w���G�J�ս誺�ۦ��{�סC�Ϥ��A��ؤ��P�M�@�ʪ��J��酶�|���b���P���i��ĤW�A��P�@�J�ս�N�o�줣�P���`肽���� (�p�� 8.5)�C
b. �ֳt�o���J�ս賡���ǦC�G �ѩ�ӭM�ͪ��Ǫ����k�o�i�A�良���J�ս誺�����E�W�A��s�H���h�ϥ��`肽�w�Ǫ���k�A�H�ֳt�˩w�ؼгJ�ս誺���� (8.1.3.3)�C�Υi�w�X�����J�ս誺�@�q�i��ħǦC��A�ϦVĶ�^�ֻħǦC�����s�ީһݪ����w�A�ΦX���H�u�`肽�H�i���M�@�ʧ��^���s�ơC 8.2.4.1 �J�ս�M�@�ʤ��ѡG �˥��J�ս�n���g�ܩʳB�z�A��T�źc�y���`肽��Ѷ}�A�~��H�J��酶���Ѥ��C a. �M�@�ʤ���酶�G���|�p�U (�i��Ĥ���) Trypsin (Lys, Arg) Chymotrypsin (Phe, Tyr, Trp) Sa protease (Asp, Glu) b. �ƾǤ����k�G CNBr (Met) 8.2.4.2 �����`肽����k�G �̪�ѩ�L�q�w�q��k���i�B�A�H�U�ާ@���F�i�H�����X�`肽���q�~�A�]�i�H���������ΰťX��a�A�e�۰ʩw�Ǥ��R�A���O�ܭ��n�������˩w�N�C a. �q�a/�h�R���V���СG �`肽���q���g���q���o�ȹq�a��A�� 90 �צA�i���o�ȼh�R�A�h�i���X�U���`肽���q�A�]�i�ϥ����h�h�R�A�����K�B�ֳt�A�o�O�зǪ���k�C b. HPLC�G �Q�� HPLC �����ѪR�O�A�ֳt�����U�q�`肽�A�h�ϥΤϬۼh�R�ެW�C c. SDS-PAGE�G �ѧ������ѩҤ��o���`肽���q�A�i�H SDS-PAGE �Ӥ��R�F�q�a��]�i�i����L�A�A�Χ��^���K�̬V��C 8.2.5 ��L������k�G 8.2.5.1 ���l�����Y�ơJ �Y�����誺�ï��A�h�i�N�w���l���� (280 nm) ���G�^�˥��A�g�N�ᰮ���D��J�ս誺�����A���o���l�����Y�ơA�H�����J�ս�w�q���̾ڡC�аѦҫe�� 5.3 �`�A�Q�Τ��l�����Y�ƨөw�q�J�ս誺��k�C 8.2.5.2 �J�ս���^���c�G a. X ��¶�g���R�O���Q�J�ս���l���c���̮ڥ���k�A���������X�J�ս赲���A��j���l�J�ս�Ө��۷������C��Ӧh�H���l��ޤ�k�A�H���{�J�ս�i�浲��¶�g���R�A�o�O�@���E�ݱM�~���ѻP���m�ޥ�����s�u�@�C b. �ϥη��G���A���J�ս�i�� NMR (�ֺϦ@��) ���R�A�i�o���G���A�U�����l�c�y�A���]���ݭn�j�q�q���B��A�]�����l�q�Ӥj�̤�����e���B�z�C c. �J�ս誺���l�c���A�øѥX���c���P��Ͳz�\�ඡ�����Y�A�O��s�ï��γJ�ս�̷��s���h���A������즹���q���פ�A�q�`���i�H�o���b�̭��n�����Z�C���]�L�L�A�]���Ҧ����Ͳz�{�H�A���i�H���l�h�����ƾǤ����Υ椬�@�ΨӸ����A�o�]�O�ͪ��ƾǬ�s���ڥ�����C �@ |
�@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ [Peptide] �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ |
|
�@ �@�@ �@ |
|
8.3 �K�̾Ǥu���G�Y��o��ï��γJ�ս誺���^�A�h��������s���D�`�j�����U�A�]�����^���M�@�ʫܰ��A�i�����M�@�ʪ����w�A�s�x�a���Φb ELISA�B�K�̨I���ΧK����L�W�C�������^���s�ƤθԲӪ�����y�{�A�аѦҬ����K�̾Ǥ��m (�p Harlow E, Lane D (1988) Antibodies, A laboratory manual. Cold Spring Harbor Laboratory)�A�H�U�q��Ψ��סA�����Ͳ����^�Ψ����Ϊ����n�ƶ��A�H�α`�����D�������C 8.3.1 �dzƧܭ�G a. �J�ս�ܭ�G �P�K�̰ʪ�����ǭI�����o�V�����J�ս�A��ܭ�ʶV�n�A���i���Q�o�찪�Ļ��ܦ�M�A�q�`�Ӫ��J�ս賣�O�ܱj���ܭ�A�Ӱʪ��ӷ����ܭ�N�n�p�ߵ����C b. �p���l�ܭ�G ���l�q�ܤp���`肽 (�b�ƤQ���i��ĥH�U��)�A�����L�k���ͧ��^�A�n�����X��j�J�ս���l�W�h (�٬� carrier�A�q�`�� BSA �� KHL hemocyanin)�C c. �b�ܭ�G ���l�q���p���@�Ǥp���l (�p���T�r���Ȧ��Ʀ�)�A�� ��hapten (�b�ܭ�)�A���� carrier ��]�i���ͧ��^�C d. �H�u�X���`肽�ܭ�G �Y�w���Y�J�ս誺�i��ħǦC�A�i�H�H�u�X���Y�q�`肽 (�j���Q�X���i���)�A�s���� carrier ��K�̥i�o�ܦ�M�C�q�`�����H�q���{�� (IEDB Analysis Resource) �w���ܭ�ʸ��j���i��ħǦC�A��X�Ƭq�i��K�̡A�i��Ǥ��q�������Ͱ��Ļ����ܦ�M�C e. �ܭ쪺�«סG �ܭ�«V���V�n�A�ר�b�s�ƶDzΧܦ�M�ɡA�«פ����i��|�������G�C���s�Ƴ����^���ܭ�i���Χ�������A�H��K�ܭ쪺�j�q�s�ơA�]���b�z��o�����^��A�i�ѧK����L�T�{���^���M�@�ʡA�h�����n�������^�C f. �ܭ쪺�Φ��G �@��J�ս�ܭ쳣�H���G�Φ��A�[�W�����B�z���a�B����i��K�� (���U�p�`)�A���]�i�۽�������L�ȤW�������a���ΤU�ӡA��H��[�����Y�i�K�̡C 8.3.2 �K�̬y�{�G a. �зǧK�̬y�{�G �� 8.6A �O�K�̤p�չ����зǬy�{�A�b�o�쨬�q���ܭ��A���ݤG��T�Ӥ몺�ɶ��ӧK�̰ʪ��C�`�g���ܭ�q�n�A���A�L�q���ܭ�A�����o�|�����n�����^�C�̪ӫ~�ƪ����į�K�̦��� (TiterMax)�A�i�H�b�@�Ӥ뤺���X���^�A�åi��֧K�̦��ơA�Ө�Ļ��]���t�C b. ��L�K�̬y�{�G ��Ӧ��\�h�ֳt�K�̤�k�A�Ҧp��ܭ�[������A�������J��Ŧ�A�H�Y�u�ɶ��ΧK�̦��ơA���Ǧ�M�Ļ����G�����C���L�K�̤����۷������A���\�h��ǤW�������{�H�A�Y�D���n�٬O�ĥμзǬy�{�A�O�߫�ϥίS����k�A���p�h�Ҷq�ܭ쪺����C
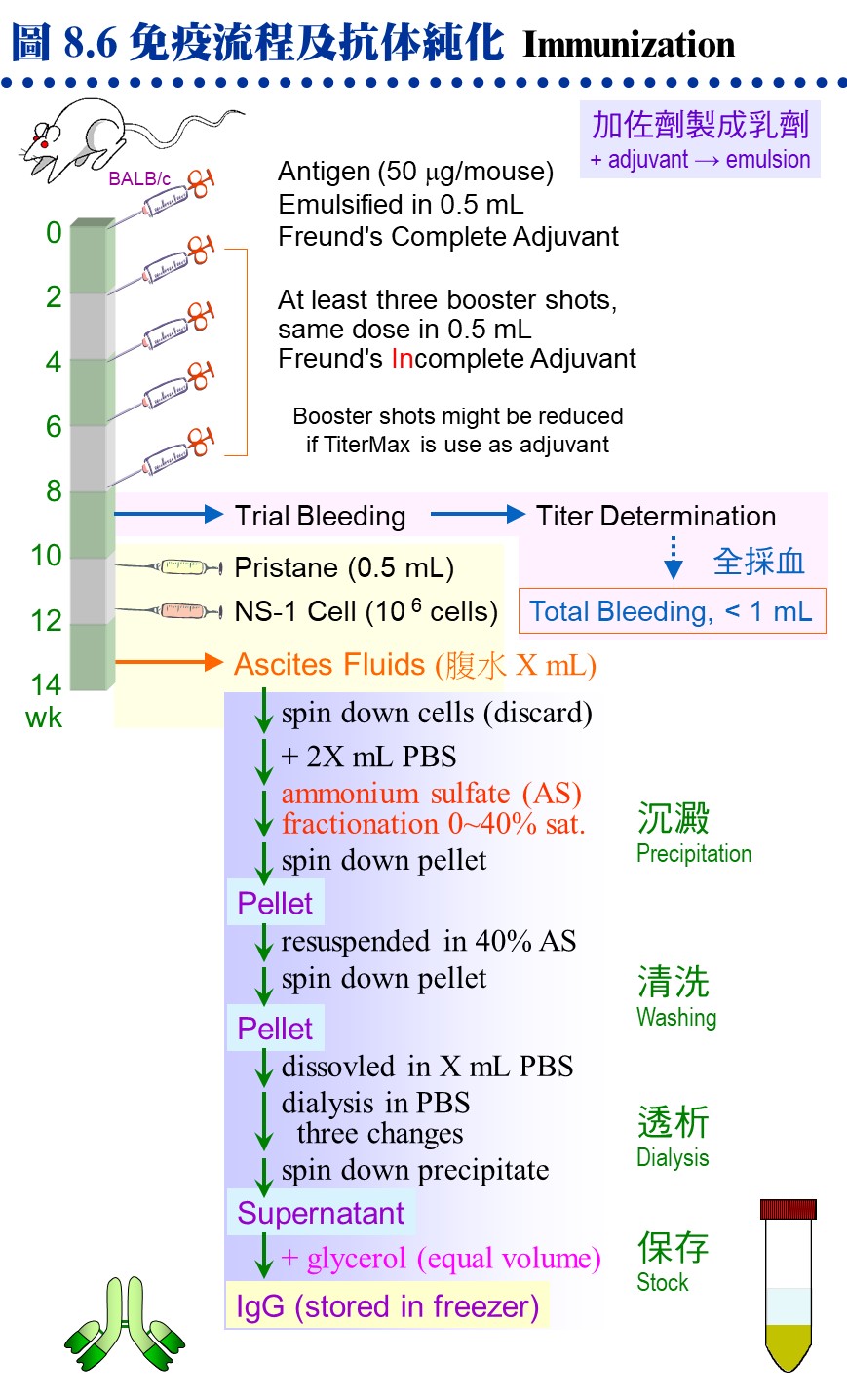
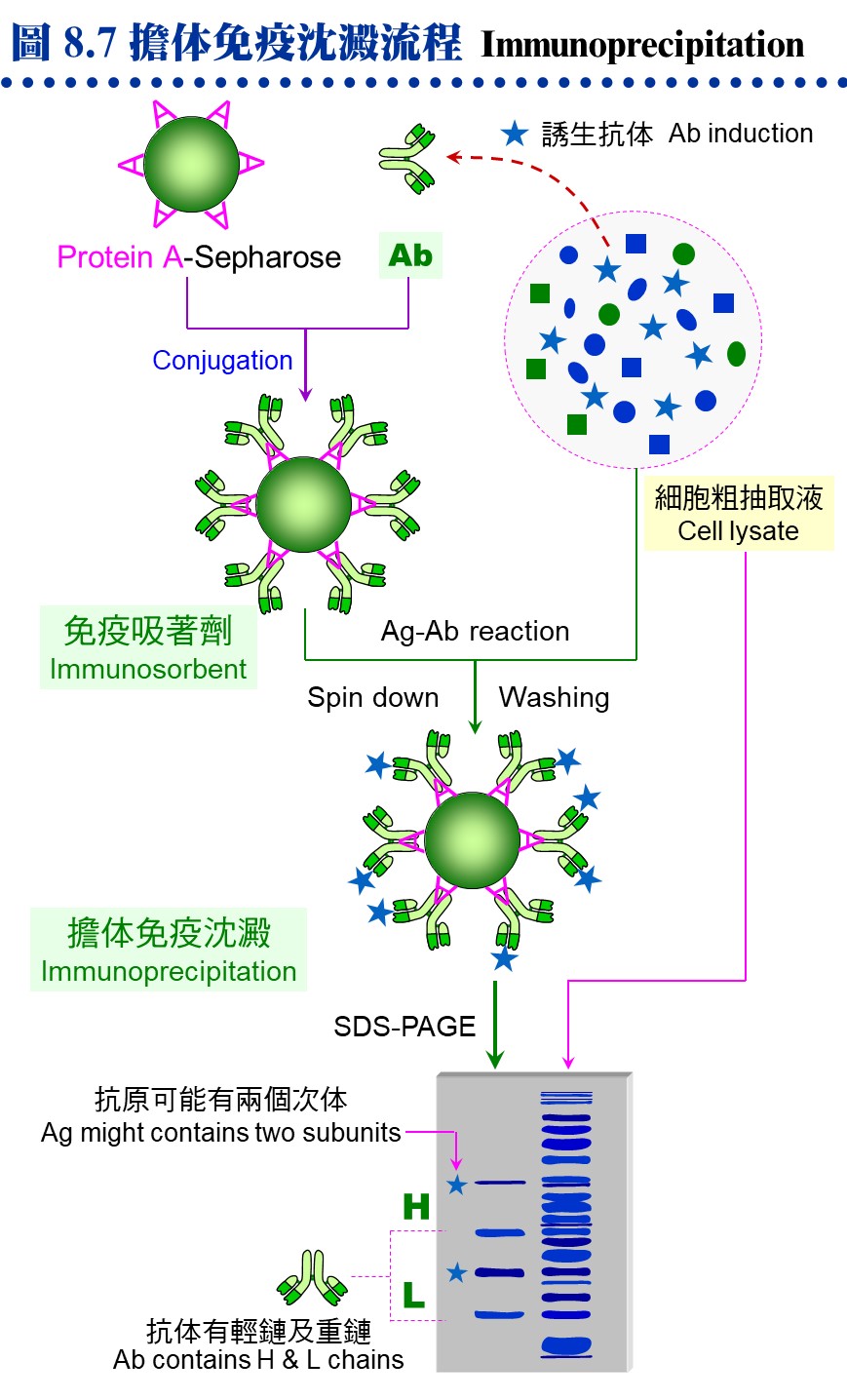
8.3.3 ���^�s�ơG a. �DzΧܦ�M�G �K�̬y�{�Φ��Ƨ�����A�i�ձĦ�ݮĻ��p��A�h�H ELISA �i����աC�Y ELISA �Ļ��F 5,000 �H�W (�Y��M�}�� 5,000 ���@�צb ELISA �� 50% �̰��e��)�A�Y�i�i������Ħ�C�ݦ�G���T��A���ߨ��W�M�Y�o�ܦ�M�A���q�ϥ��a�Ŧ����߾��C b. �����Ķ��G �p��������q�ܤ֡A���Y���ͨ両���A�h�^�n�i�W�j�\�h�C�p�� 8.4A �y�{�����I�� pristane ��z�p���K�̤O�A�A���������ӭM NS-1 �i�両�ġA�i�������@�ܼƲ@�ɡC�������h�����^�A�i�i�@�B�¤ƥX���^�C c. �����^�G �����^�w���@�ܭ�M�w�������M�@�ʡA�O�DzΧܦ�M�ҵL�k�F�P���S�I�A��J�ս�ӷL�c�y�����R�ܦ��γB�C��s�ƹL�{�۷������A�ާ@���Q���ܡA�e��i��ݮɤT�Ӥ�H�W�A���Y�N�P�]�Ƨ������A�n���o���Ϊ������^�ëD���ơC (���a���G�ӭM�ĦX�P������) d. �K�̲y�J�աG �L�O�o��ܦ�M�θ����A�������ֶi��K�̲y�J�� (Ig) ���¤ơA�q�`�u�n���ĻϨI���Y�i�o��۷��ª��K�̲y�J�� (�� 8.6B)�C�n�`�N�o�˩ұo�쪺���^�A�䤤�u���@�����O�M�@�ʧ��^�A�]���ʪ��������\�h����N�s�b�����^�A���D�O�ĦX�F�ӭM�Ҳ��ͪ������^�C 8.3.4 ���^���ΡG a. ��L�ΧK�̬V��k�G �O���^�b�ͤƤΤ��l�ͪ��Ǭ�s�̭��n���^�m�A��Բӻ����Ш� 7.3.2 �ҭz�C b. �K�̨I���k�G �Y����^���l���b�@�T�۾��^�W (�j�h�ϥ� CNBr-Sepharose)�A�h�i�ΨӰ����M�@�ʪ��I�����A��˥������ܭ���l�M�@�ʦa�H���U�� (�� 8.7)�C
c. �˩M�h�R�k�G(�Ѧ� 2.4) �W�z�������^���T�۾��^�A�]�i�κެW�覡�i��˩M�h�R�A�H�¤Ƨܭ���l�A�N�b�ï��¤Ƥ�k�������C d. ���V�K���X���k�G �۷��j�Ѫ��K�̾��˩w�k�A���������ΤW���S��C�Q�Φb�v�潦�^�W�X�����H���ϧΡA���˩w�ܭ�Χ��^�����M�@�ʤ����A�åiŲ�O��ܭ���l���c�y�W���t���C e. �ï��K�̤��R�k (ELISA)�G ��z�P�K�̬V��k�����A�O�Q�Χ��^���M�@�ʥh�����ܭ�q���h��A�åH�ï�����j�H�����ХܡA�]�����۷������F�ӫסC�]���ϥ� ELISA plate ���T�ۡA�G�ާ@�۷���K�A�P�ɥi�B�z�j�q�˥��A���ѪR�O���ιq�a��L���K�̬V��k�C �@ |
�@ �@ �@ �@ �@ [Antibody] �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ |
8.4 �J�ս�s����G���l�ͪ��ǧֳt�o�i 50 �~�A��ֻĪ��A�Ѳֿn�۷���¦�A�ӥѮֻĩҪ��{���J�ս�A�]���{�䭫�n�ʡC�s���J�ս��ޡA���F�j�ƶDzΪ��¤ƻP�˩w��O���~�A�ޤJ�L�q��ު������A�J�ս誺���R�V�ӶV��K�B�F�ӥB�ֳt�A�һݼ˥��q�]�V�ӶV�֡C�P�ɡA������H�]�ѳ�@�J�ս�i�J�J�ս��^�A�H��j�槽�h�ݾ�ӲӭM�D�ܥͪ��^�����ʡC 8.4.1 �L�q��ޡG ���M�DzΪ��J�ս�����¤ƧN�A�b��B�����Τj�q�¤ƤW���M�ܭ��n�A�����ֶq�˥��ΰ�]�s�ު��{�X�Ӫ��J�ս�A�h�b�¤Ƶ������������۷��j�����ܡC�q�`���A��d��@�B�B���¤Ƥu�@�A���A�B�B���D���ʦ^���ί¤ƭ��ơA�ӥH�@�اֳt�F�����y�{�A�ܧ���w�ҭn���J�ս�A���X�ֶq����J�ի�K�i�J�L�q�w�Ǫ��˩w�u�@�A�i���W�o���ӳJ�ս誺�����C�o�رj�������������A�n�a�H�U�L�q�¤Ƥ��˩w�t�Ϊ��إP�o���C���M�ާ@�������ܤơA���J�ս�¤Ƥ��R����z�O���|���ܪ��C 8.4.1.1 �L�q�¤ơG ��z���O�y�ݱo�쪺�A�N���o���z (what you see, what you get)�A�q�`�O�Q�ιq�a�� HPLC �����A�����ҭn����a�Φy�p�A�U���C�X�X�Ӱ�k�C a. SDS-PAGE ����L�G(�Ѧ� 7.3.2) ���������B���˥��A�b�g�L�@�몺�q�a����L��A�Y�i�o�찮�b����a�A��W�U���L�z�Z����a�A�h�i�b�w�����X�ҭn����a�A�ߧY�e�h���л��T�w�����C b. �G�����q�a�G(�Ѧ� 7.3.4) �Y�W�z��k�L�k���o��@�J�ս��a�A�h���H�G�����q�a����L�A���X�ҭn�����I�A���X����A�e�w�ǡC�H�W�B�J�H�� 8.8 �K����i��y�{�C
c. ���^�����ѡG ���@�Ӭ۷��`�����x�Z�A�N�O�\�h�J�ս誺 N-�ݳQ���A�]�N�L�k�����H Edman degradation �w�ǡC�Y�J�ս�q���j�A�h�i�b�պޤ��i��h�����ƾǤ����A���q�`�S�������J�ս�C�]���A�i�H�b�W�z�U�عq�a�������A�������X�ҭn����a�A�b���^���H�J��酶�i����ѡA�ұo�쪺�`肽���q�A�A�g HPLC ������e���л��i��w�ǡA�{�b�o�˥ѽ��^����Ф��R���L�{�A���i�b�@�e�y�{������ (�� 8.8)�C d. �L�q�¤ƨt�ΡG HPLC �� FPLC ���A�X�����L�q�����u��A��ӤS����Ӻq�a�Τ�Ӻ� LC�A���q�`�b�i��o�ǷL�q�������e�A���n���H�DzΪ�������k�i�泡���¤ơC 8.4.1.2 �L�q���R�G ����o�i����A���R�������F�ӫV�ӶV���A�]���һݼ˥����q�]�V�ӶV�֡A�b�¤ƤW�i�H��֫ܦh�·СA���]���F�ӫװ��A�]����e��������z�Z �A�Ʀܱ`������ֽ��B�Y�֮h�z�Z���רҡC�`�Ϊ����R��k�p�U�A�q�`���O�������Q���j�������A�ҩ��]���ܦh�ӷ~�A�ȡC a. �J�ս�w�ǡG(�Ѧ� 8.2.3) �٬O�H Edman degradation ����¦�A���F�ӫץi�F 10~100 pmole�A�]���@�ӹq�a����a�w�����w�ǡC�@��i�w�X 10-30 ���i��ħǦC�A���ǦC�Y�i��J�q���A�H�n�^�p Lasergene (DNASTAR) �j�M�ۦ����J�ս�A�N�i���w�䨭���C b. ���л����R�G(�Ѧ� 8.1.3.3) ���л��i�H��T�˩w�˥������l�q�A�]���J�ս���ѫ᪺���q�A�i�ν��л���T�w�q�D�o���l�q�A�ӥثe�H���л��i���`肽���q���w�Ǥ]�������D�A��i���X�����q�W���U�ح��A�Ҧp�C�ĤơB�ޤƭ����C�q�`���л����R�b LC ��������i��A�g�� LC/Mass �� LC/Mass/Mass�A�ݫ᭱���۴X�����Ф��R�C 8.4.2 �J�ս��^�ǡG �i�J 21 �@����ͪ��Ǫ��Ĥ@��j�ơA�N�O�H�^��]���ֻħǦC�����ѽX�A�o�O���� Genome Project ���E�j�u�{�C�b�o��H�^�Ҧ�����]�ǦC��A�Ĥ@��i�H�����ơA�N�O��o�ǰ�]�Ҫ��{���J�ս�½Ķ�X�ӡA�i�@�ӥͪ������^�J�ս��^�A�p���Q�ҽk�٬� proteomics ���O�@���e�j��Ʈw�A�i��L������ĤζW�X�Q�����o�i�C 8.4.2.1 �p��ݫ� proteomics? a. �H�ۥͪ������B�����ձ��B�~�Ӧ]�����v�T�A�@�إͪ��� genome �i�H���{�X�\�h���P�� proteomes�A�]���J�ս��^�O���]�^��������s��H�C b. ��]�^���G�N�O�û��b�ӭM�ָ̡A�M�ӳJ�ս�Q���{�X�Ӥ���A���������B�ոˡB�B�e���L�{�A�]���俳�I���ͩR�g���A�]���ͪ��ӭM�èS���@�өT�w���J�ս��^�A���û��b�ܤƵۡC c. �M�ӳJ�ս��^�]����۹���w���@���A���M�U���J�ս誺�c�y���D�`�����h�ˡA���]�i�k�ǥX�X�ذc�y (module)�A�ӳo�� modules ���\��j���i�H�w���C�c�y�������J�ս�A�X�G���֦��ۦP���\��A���i��ħǦC���N�i�ǽT�w���C d. ��]�^���j�p�P�ͪ��������פ��@�w������A�Ҧp�H������]�ƥب��ä��h�A�]��������ץi��Ӧ۳J�ս誺���ձ��A�ƩγJ�ս�^�X�h�ո`��]���{�C 8.4.2.2 Proteomics �N�O�J�ս�ƾǡH a. ���T�J�ս��^���L�[��¦�N�O�DzΪ� �J�ս�ƾ� protein chemistry�A��̳q�`�w���@�J�ս�i��ӳ������R��s�A���[�J�ս��^�h�X�j�槽�P�d��A�H������B��ֳt�B�W�L�q�����ݤ��R�����A���˵���ӲӭM�Υͪ��^�����^�J�ս�A�b��s�A�P�ϥΪ��u��W�A�����ܤj�����P�A���G�̬O�K�������C b. �J�ս�ƾdzq�`�H�o���ӳJ�ս���l���ǦC���ؼСA�ӳJ�ս��^�ǤϦӥu�n�����ǦC�A�t�X�ͪ���T�Ǫ��e�j��Ʈw�A�����ǦC�w���HŲ�w�����J�ս�A�åѦ��`�J���ɧ�h�Ӹ`�A���I�쭱���X�i��s�h���C�i�����h������s�ɡA���ŧѰO�b�J�ս�ƾǪ���¦�W�A�t�X�ͪ���T�dzo�ӱj�j���u��C c. �DzγJ�ս�ƾǻE�J�b�ּƥؼгJ�ս誺�c�y�\�����Y�A�@�B�@�B�a�ѨM���D�A���p�@���j�Ԫ��}�a�����ԡC�M�ӳJ�ս��^�Ƕե��n�[�J �t�Υͪ��� (systems biology) �����s�}��A�p�X��]�^�B����^�B�N���^�B�H���ǾɡA�H�Υ���w���Υ������ӭM�ͪ����^�t�A�@�_�Q�Τj��Ʈw�B�Ʀ�B��B�έp���R�B�����w�����A�гy�X��h�˦ӥ��^���[��t�ΡA����e�ҥ������ͪ��B�@�Ҧ��C 8.4.2.3 Proteomics �P�N���^�G a. �ˬd�@�ӥͪ��J�ս��^���Ҧ��ï��A�����i�H����X�Y�ӭM���N�³~�|�C�Ҧp���ڭ̬ݨ�Y�f��ߪ��J�ս��^�� hexokinase�A�H�Ψ䥦������ glycolysis �ï��A�h�i���_���ߦ��}�ѧ@�ΡA�Ʀܦ���U�媺 TCA cycle ���C���~�A�H���Ǿɤ]�O�@���e�j�����A�J�ս��^�Ǥ@�w�|�o�����n�\��C b. �p���i�A�Ѹӯf��ߪ����^�N�»P�ǾɡA�ç�X��S���z�I�[�H�����F�Ϥ��]�i�H���ܤ@�Ӧ��q�ߪ��N�¡A�Ϩ�N�²��������ŦX�H�����ݭn�CJ. Craig Venter �b 2010 �~�s�y�H�u���V���^�A�åB�ޤJ��ߵߪŴߡA�ź٬��Ĥ@�ӤH�y�ӭM�C c. ��DzΥͪ��ƾǪ��N�³����A���Ӧ����s������P�{���A���M�u�����C�@���N�¸��|�����|���ܤơA���ڭ̶ե��o���s�X�o�A�H�J�ս��^���߱���Ū����N�¡A�H��j�槽�h�s���U���N�ª����ʡA�γ\�N�O�һ��� �N���^�� (metabolomics)�C d. �H���j�����e�f�X�G���P�N�¦����A�]�i�H�b��]�^�W���ڷ��A�]���Y��ХX�y���f�ܪ���]�A�]�N���X�y���f�ܪ��лx�J�ս� (marker protein)�A�ӳo�ǯf�ܳJ�ս�ܦh�N�O�ï��A�f�ܳs���ۻï����ʤΥ\��ʳ��A�o�]�O����ڭ̭n�p�������ï���s���D�]���@�C �@ |
�@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ �@ (TED: JC Venter: �@ �@ |
���D�� (�C�Ӱ��D���@�w�����зǵ��סA�Ʀܷ|�ް_�ܤj����ij�A���o�N�O���D�����D�n�ت�)1. �A�b�¤Ʊo�Y�ï���A�g�w�DZo��� N-�ݪ� 15 ���i��ħǦC�A�аݱ��ۥi�H�i�樺�ǹ���H�U����ت��Υγ~�H [2] 2. �q�a��i��J�ս���L�A�A�Χ��^�V���A���G�G [3] a. �o�{��i��L�Ȥ@���ťաA�б����i���]�C b. �o�{���F�зǫ~���Ŧ��a�s�b���~�A��l�U�˥��ťդ@���A�б����i���]�C 3. �Y�A���J�ս� N-�ݤw�Q�A�Q�ơA�L�k�i���i��ĩw�ǡA�h�A�N�p��w�X�ӳJ�ս誺�����ǦC�H [2] 4. �i��IJզ����R�i�o���J�ս褤�U���i��Ħʤ���A�� Asn �|���Ѧ� Asp�AGlu ���Ѧ� Glu�C�]�N�O���u����o��̪��M (�H Asx �� Glx ����)�A�ӵL�k�������o Asn �� Gln ���q�C�аݧA�p��i�H���X�Ҵ��o�� Glu (Asp) ���t�h�� Gln (Asn)�H [3] 5. ������u�� Edman ����������Φb�i��ĩw�ǡH�� dansylation ����H [2] 6. ���л��D�n�O�ھڤ��l���q����q�Ӱ����R���A�ثe�j�P����j�����R�覡�A���O�H MALDI-TOF �� ESI-Mass ���N���A��̦b���R��z�Ψ����ΤW���P�H [2] 7. ESI-���л����R�i�H�w�X�J�ս誺�i��ħǦC�A���N�n�ζw����l��J�ս襴�H�ܦ���p���`肽���q�A�ӨC�Ӥ��q�����u���@���i��Ĥ��t�O�A�b���@�s��o�˪��`肽���q����A�N�i�H��X�i��ħǦC�C���M�b���H�J�ս�ɡA�J�ս���l�W�C���䵲�Q���������v�O�ۦP���A����ڤW�`肽��Q���������v�����A�]���۹�e���o��u�t�@���i��Ĥ����q�A�б��������`肽�����e���Q�����H [5] 8. �K�̤ƾǮѤW����A���^�i�H�P�ܭ쵲�X�ӨI���U�ӡA���b�ͪ��ƾǤ����ήɡA�����^�q�`���n���b�@�T�۾��^�W�A�~�వ���K�̨I�����C����n�p���·СA�������H���^�ӨI���ܭ�H [3] 9. ���s�ޱo�Y�ï��� cDNA �äw�w�ǡA���䬡�ʤ��R��k�����x���A�ήڥ��������ï������ʮɡA�h�b�¤ƹL�{���A�A�����k�i�H�l�ܦ��ï��H [4] 10. �Ͳ��DzΧ��^�ɡA�ܭ�«פ@�w�n�D�`���A�_�h�i��|����e�����A���b�Ͳ������^�ɡA�Ϧӥi�H�Τ��ܯª��ܭ�h�K�̡C�аݳo�n�p��i��H������M����H [5] 11.�����C��酶�P b-����酶����賣�O�����A����̪��ʤƤ������P�A���l�c�y�W�]�L�ۦP���B�C���ϥξ����C��酶���ܭ�s�Ƴ����^�ɡA�o�{�ұo�쪺���^���ܦh�� (���@�b) ���|�� b-����酶����e�����A�Ϥ��Y�H b-����酶���ܭ�ұo�����^�A�]���ֳ���������C��酶�|�������C�и����o�O�p��y�����H [4] 12.�J�ս���L��A�H�K�̬V��ұo�V���a���`�L�A��_�����w�q�J�ս誺�̾ڡH�аݳo�˪��w�q��k�A���L�i����~�H�p���i�Ϊ`�N�H [4] 13.�Y��u���`肽 (���Q�h���i���) �s�� carrier �W�����ܭ�A�i��K�̫�i�H�o����^�A�٬� monospecific Ab�C�Y�ͥѨ�ï� cDNA �ǦC��Ķ���J�ս�ǦC�W��X�@�q�S���ǦC���`肽 (VALIWVVSAIL)�A�H���i����^�s�ơA���G�]�o��F���^�C���o�{�����^�b�i��J�ս���L���K�̬V��ɡA�� disc-PAGE ��������L���L�k�e��A�ӧe�@���ťաA�P�ɹ� SDS-PAGE ��L���A�h�u��ݨ�ܲH����a�C�аݵo�ͤF�����f�H�p��ѨM���D�H [4*] 14.��W�@�D�A���]���ͱo��t�@�ا������P�����G�ASDS-PAGE �K����L�o��ܱj���e���a�A����ӭM���ʩ���G�˥����˩w�ɡA�藍�t���@�ï�������աA�o�]���K�̧e��A�аݦp������H [5] 15.��W���D�A�t�@��P�ǫh�H�q���n�^�j�M���j���ܭ�M�w��A��F�ӳJ�ս�ܾa�� N-�ݪ��@�q�ǦC (MILAKKSVALV)�A�P�˶i����^�s�ơA�ұo���^��ӭM���ʩ���G�˥����˩w�A���G�b��� PAGE �����W�w�����l�q����m�A�����ݤ���e�⪺��a�A���b�w�����l�q�y���B�A�����o�{���@�ܲH�S�ܲӪ���a�C�o�S�O�o�ͤF������D�H [5] 16.�V�y�P�f�r (AIV) �~�ߦ��@�ئ�G������ (hemagglutinin, HA)�A�O�J�I�J�D�ӭM��������l�AHA �P�J�D�ӭM���W�������鵲�X�A���۱Ұʤ@�s�����A��f�r��]�e�i�ӭM���A�}�l�f�r���P�V�B�c�ޡB�X���ͬ��v�CHA �b�J�D�餺�Q���}�� HA1 �� HA2 �ⳡ���~�����`�\��A�����M���������c�y�FHA �]�|�Q�ޤ� (glycosylated)�A�i��O�@�f�r���\��C�H H6N1 (2838V) �� HA1 ���ҡA�q���i��ħǦC�w�����ƭ��ޤƦ�m�A�Y���i��h�ޤƳB�z (�U�� A �� P +)�A�h HA1 �����l�q�� a ���� b�A�A���O�� a �� b ���X�ӥH trypsin ���Ѧ����q��i����л����R�A�U���q�ǦC���R���G�p B �ϡA�o�{ b �� a �h�X�T�Ӥ��q�A�л����o�ӵ��G���@�ξ���O�p��i�檺�C[4*]
[�D�ث᭱��A�������Ʀr�N�����D�������{�סA3 �������� 5 �����^���A�Ц� * ����ڰ��D] |
�@ �@ �@ �@ �@ �@ �@ �@ �@ �@ |
| �� |