|
|
生物化學基礎 Biochemistry Basics 2008 |
回核酸 3 |
|
|
||
|
■■■ |

%202007/NA4-1.JPG) |
|
核酸 的研究技術,大多已散佈在上述構造與性質的說明中,因此只補充說明未提及的部分。以下整理這幾十年來,有關基因操作方面,在生物技術應用上的重大發展方向︰ (1) 基因轉殖生物體 (genetic modified organism, GMO) (2) 基因治療法 (gene therapy) (3) 生物個體複製 (somatic cell cloning) (4) 幹細胞分化及人造器官 (stem cell differentiation) (5) 基因體計畫 (genome projects) (6) 生物資訊學 (bioinformatics) (7) 蛋白質體研究 (proteomics) (8) 生物晶片 (biochips) |
%202007/NA4-2.JPG) |
|
PCR 是聚合脢連鎖反應的縮寫,可以把指定的基因片段數量放大。但必須知道目標基因的起始及終結的部分序列,以便分別製得界定起點與終點的兩個引子。如此,聚合脢便會在兩個引子之間複製 DNA,所得到的複製品,可在變性後再度黏合引子,進行次番複製;如此來回重複多次,即可得到大量介於兩個引子之間的核酸片段。 PCR 技術剛被發展出來的時候,居然不受重視,後來發現越來越多的重要應用;不但在研究上有貢獻,在分子診斷與法醫學上更是大放異彩。 ◆ PCR 的基因放大作用 (以動畫呈現 PCR 如何把特定基因放大) |
%202007/NA4-3.JPG) |
|
核酸 的純化方法相當固定,除了因材料不同所可能導致的特殊抽取問題外,處理核酸的方法大致都相同。所有核酸都可以被乙醇沈澱,但其中只有 DNA 因其分子很長,可以使用玻璃棒撈取之,乾燥後再以緩衝液溶出,就可以得到粗的 DNA 材料。利用限制脢可以把 DNA 切成特定片段,再以電泳檢視。不同種類的 DNA 在抽出後進行限制脢水解,所得到片段的電泳圖譜,大概都不會相同,是一種重要的生物鑑定方法。 |
%202007/NA4-4.JPG) |
|
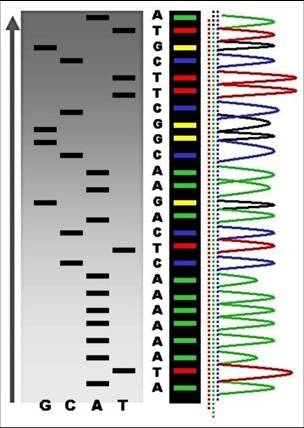
核酸
定序方法的關鍵方法,在於如何製得一系列的核酸片段,而這些片段各中止於不同的鹼基位置;一個鹼基的差異,即可用電泳分析出來
(上圖左)。其次,要把具有相同尾端鹼基的片段提出來 (例如 T),放在一起進行電泳,則分別有 A, T, C, G 四條電泳
(上圖右)。比較這樣的四條電泳圖譜,依序判讀色帶出現的先後,即可推出序列。有兩種方法可製備一系列長度不同的核酸片段,請見下一頁。
目前大多定序工作已經自動化,並且利用新的螢光標示物質,以及靈敏螢光檢測器,可以直接以顏色辨認鹼基的種類。另外,也改用毛細管電泳或
HPLC 進行核酸片段的分離,使得定序的進行更為快速而精確,請看下右圖以彩色標示如此分離出來的片段,馬上可以唸出核酸序列
(Wikipedia) 。
|
%202007/NA4-5.JPG) |
|
(1) Maxam-Gilbert 法: 以不同化學反應分別對四種鹼基作用,每一反應只對一種鹼基進行修飾,而在該鹼基的地方斷開,得到一系列長度不同的核酸片段。 電泳可依照這些 DNA 片段的大小,在膠體中排開,即可依序判讀 DNA 分子上核苷酸的序列;比較如此四組鹼基序列電泳,即可組合成整段 DNA。 事實上第一步只有兩種反應,分別對 purine 與 pyrimidine 反應,然後再利用其他方法分辨 A, G (或 C, T)。 (2) Sanger 法: 以樣本 DNA 為模板,使用 DNA polymerase 進行試管中 DNA 生合成。 有四個反應,每個反應各缺乏一種核苷酸,而代以其類似物 (analogue),可以被接納進入反應,但是無法繼續下一個反應,因此合成會停在該類似物的核苷酸處,因而造成各種長短不一的 DNA 片段,以電泳分離如上頁,即可組合判讀 DNA 的序列。 上述兩種方法,均以 32P 標示在核酸分子上,以便顯像各不同長度的核酸片段。 |
%202007/NA4-6.JPG) |
|
目前 都用 Sanger 的生合成法,以目標核酸為模板,加入四種核苷酸及 polymerase,複製該段核酸;但除了所加的四種核苷酸外,額外加入其中任一種核苷酸的雙去氧衍生物 (類似物 dideoxynucleotide),合成反應可能止於這種核苷酸的位置,因而可得到各種長短不同的片段,再以電泳依序排列出來。 問題:現在有很多人要想出更方便的核酸定序方法,你能否也設計一些? |
%202007/NA4-7.JPG) |
|
定點突變 是使用人工合成的引子,先與目標基因雜合 (2),而此引子的核苷酸序列與目標基因互補,但其上有一個核苷酸變異 (GTC→GCC)。然後補滿雙股核酸 (3),再把此混成基因轉殖進入宿主,則宿主菌的複製系統將會因複製而產生兩種質體 (4),其一為原來的野生型,轉譯得原來的蛋白質 (5);另一則為突變型,轉譯則得到突變蛋白質,但只改變了一個指定位置的胺基酸 (6)。 問題:定點突變在研究 (1) 蛋白質構造或者 (2) 酵素催化反應,非常有用。你能否舉出一些可能的應用實例? |
%202007/NA4-8.JPG) |
|
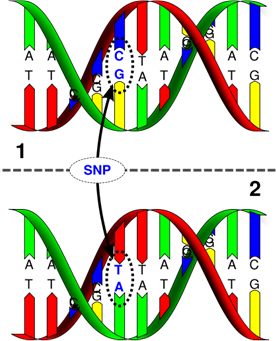
限制脢圖譜多形性 (Restriction fragment length polymorphism) 可用來檢定兩種生物或個體在分子演化上的親疏關係。雖然同一群族內的每個個體,其基因組成大同小異,但是個體間仍然會有微小的差異,也就是說其基因序列並不完全相同,稱為多形性。而基因序列的不同,也會使得限制脢所能辨認的位置,可能有所差別;因此兩個個體的相對應基因,若以同一限制脢水解,就可能切出不同的片段出來。 生物染色體的核酸序列經常會有變異,很多都是發生在單一個鹼基,稱為 single nucleotide polymorphism (SNP)。人類染色體中每 100~300 個鹼基,就可能有一個 SNP。這些單點變異可能根本不會影響到後來表現出來的蛋白質 (為什麼?),但也有可能是某些疾病的根源。 (右 下圖 Wikipedia)。 那麼,人類基因計畫所定出來基因序列,到底是一個人的? 或者是許多人的? 據主持計畫的 Venter 說,賽拉雷是取用五、六名匿名自願者的基因,進行選殖定序,其中也可能包括他自己的基因。
|
|
■■■ |